Применение статистического метода в генетическом анализе позволило Менделю установить основные законы наследования.
Для того чтобы при скрещивании у животных и высших растений все фенотипические классы проявились в расщеплении, необходимо равновероятное образование разных сортов гамет и осуществление всех возможных их сочетаний при оплодотворении. Например, гибридное мужское растение Аа производит равное число пыльцевых зерен А и а, а женское, гомозиготное по а, производит одинаковые яйцеклетки. Однако при опылении на каждую яйцеклетку с аллелью а может приходиться как малое, так и большое число пыльцевых зерен. При малом их числе нет гарантии, что оба сорта пыльцы (А и а) окажутся в равном соотношении, так как одних пыльцевых зерен в силу случайности может быть больше, а других меньше. При большом же их числе вероятность того, что они будут с одинаковой частотой соединяться с яйцеклетками данного типа, возрастает.
Следовательно, важным условием реализации расщепления является размер, или объем, выборки, оцениваемой в опыте. Чем меньше количество особей в анализируемом потомстве, тем более вероятно случайное отклонение от нормального расщепления. Значение объема выборки еще более возрастает, если при оплодотворении сочетаются два сорта яйцеклеток — А и а и два сорта спермиев — А и а, так как здесь возрастает момент случайности. Чем больше элементов (сортов гамет) участвует в сочетании при прочих равных условиях, тем большего объема необходима выборка для наилучшего совпадения эмпирического расщепления с теоретически ожидаемым.
В гаплофазе расщепление учитывается на гаметах, а в диплофазе на зиготах и организмах. В последнем случае от мейоза до проявления признака протекают сложные процессы, которые могут маскировать результаты расщепления, при этом часть зигот может погибнуть; кроме того, признаки, определяемые генами, могут измениться под влиянием различных негенетических факторов.
Само явление расщепления является биологическим, а проявление его носит статистический характер. Поэтому в экспериментальной работе каждый раз необходимо убедиться в том, является ли обнаруженное отклонение от теоретически ожидаемого расщепления (1 : 1; 3 : 1; 9 : 3 : 3 : 1) отклонением, вызванным закономерным влиянием каких-то факторов, нарушающих расщепление, или оно случайно, обусловлено, например, недостаточной величиной выборки.
В статистике принята считать, что если отклонение встречается чаще, чем 1 на 20 проб, то оно не случайно. Для оценки соответствия фактического расщепления теоретически ожидаемому необходимо определять значение отклонения.
Для статистической оценки отклонения применяют метод χ2 (хи-квадрат). Расчеты с помощью этого метода производят следующим образом. Сначала составляют таблицу по классам расщепления на основании опытных числовых данных. Затем из суммы частот всех классов, составляющей объем выборки, вычисляются теоретически ожидаемые величины (q) для каждого класса соответственно предполагаемой формуле расщепления (1:1, 3:1, 9 : 3 : 3 : 1 и т. п.). Далее определяют отклонение (d) полученных данных от теоретически ожидаемых для каждого класса.
Каждое отклонение d возводят в квадрат, и квадрат отклонений (d2) делят на теоретически ожидаемое число (q) для данного класса:
d2/q
Все частные суммируют и получают величину χ2:
χ2 = Σ (d2/q)
Чтобы убедиться в том, что одинаковые отклонения могут иметь разное значение в зависимости от объема выборки, разберем пример расщепления по одной паре аллелей — черная и серая окраска мух при анализирующем скрещивании в опытах с дрозофилой. Теоретически ожидаемое отношение в данном скрещивании 1:1. Допустим, что один студент ограничивается в опыте 60 особями, другой получает больше — 300 особей. Как показывают данные, абсолютов отклонения одинаковы как для большой, так и для малой выборки, но величина χ2 гораздо больше для малой.
По методу χ2 можно определить вероятность того, насколько данное отклонение является случайным или, наоборот, закономерным. Производится это с помощью специальной таблицы Фишера.
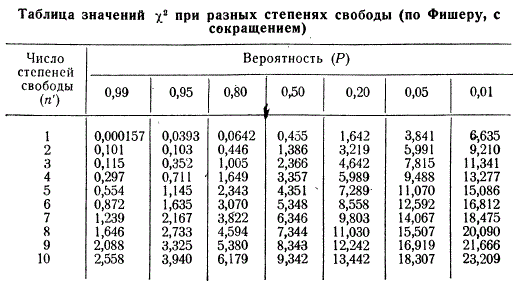
Чтобы определить вероятность соответствия опытных и теоретически ожидаемых данных (Р) по данной величине χ2, необходимо сначала выяснить число степеней свободы. Отношения 1 : 1 и 3 : 1, т. е. в каждом по два класса, можно представить в виде суммы двух слагаемых, одно из которых устанавливается свободно, а второе — в зависимости от первого. В данном случае степень свободы может быть только одна. Чтобы было ясно, что такое степень свободы, приведем примеры.
В группе из 60 особей встречаются только два класса мух (черные и серые). Известно, что 40 из них серые. Если правильно отобрать 40 серых мух, то во втором классе автоматически будут только черные, и их должно быть 20, т. е. из суммы двух слагаемых одно взято свободно, а второе определилось автоматически. Если в F2 имеет место расщепление на три фенотипических класса (АА : Аа : аа), то после учета одного из них останется еще возможность выбора второго класса, а третий класс будет определен автоматически; из суммы трех слагаемых два берутся свободно, а третье имеет зависимое значение и т. д. Таким образом, число степеней свободы при анализе классов расщепления всегда будет на единицу меньше числа последних, т. е. если n — числа, классов, то число степеней свободы и будет равно n′ = n — 1.
В приведенном выше примере при двух классах расщепления степень свободы будет только одна. Вычислив величины χ2 отыскиваем соответствующие им вероятности для одной степени свободы по таблице Фишера. Так, для выборки в 60 особей, где χ2 = 6,6, вероятность Р будет меньше 0,01 т. е. соответствие теоретических и фактически полученных данных будет наблюдаться реже чем раз на 100. Однако, как мы уже говорили, в статистике считают явление случайным, если оно встречается реже, чем 1 раз на 20 проб (0,05). Иначе говоря, расщепление 40 : 20 не соответствует 1:1. Во второй выборке в 300 особей χ2 = 1,34. Находя соответствующее ему значение вероятности по той же таблице, мы убеждаемся в совпадении опытных данных с теоретически ожидаемыми: 0,50 > Р > 0,20, т. е. Р = 0,2 ~ 0,5, что указывает на соответствие получаемых и ожидаемых частот примерно в 1 случае из каждых 2.
Тем же путем можно высчитать достоверность различий при дигибридном расщеплении по признакам семян гороха, полученном в опытах Менделя.
Метод χ2 дает возможность сравнивать различные численные отклонения при разных объемах выборок в одном масштабе, что очень важно для оценки опытных данных. Но следует иметь в виду, что этот метод неприменим, во-первых, к значениям, выраженным в процентах и относительных числах, и, во-вторых, к выборкам с числом особей в каком-либо из теоретически рассчитанных классов, меньшем, чем 5.